If any release contains only the modules which has been changed, it is called to be delta release.Also known as partial release , delta release is one that includes only those areas within the release unit that have changed or are new since the last full release or delta release.
Wednesday, 10 February 2016
MT - 71 - What is test log?
The IEEE Std. 829-1998 defines a test log as a chronological record of relevant details about the execution of test cases. It's a detailed view of activity and events given in chronological manner. Testlog is a repository to store passed and failed testcases. Test log is document which records all test result of different activities which are both pass and fail criteria
The following figure shows a test log and is followed by a sample test log.

The following figure shows a test log and is followed by a sample test log.
MT - 70 - Testing Standards !!
Some widely used standards related to Quality Assurance and Testing :
ISO/IEC 9126
This standard deals with the following aspects to determine the quality of a software application:
- Quality model
- External metrics
- Internal metrics
- Quality in use metrics
This standard presents some set of quality attributes for any software such as:
- Functionality
- Reliability
- Usability
- Efficiency
- Maintainability
- Portability
ISO/IEC 9241-11
This standard proposed a framework that describes the usability components and the relationship between them. In this standard, the usability is considered in terms of user performance and satisfaction. According to ISO 9241-11, usability depends on context of use and the level of usability will change as the context changes.
ISO/IEC 25000:2005
ISO/IEC 25000:2005 is commonly known as the standard that provides the guidelines for Software Quality Requirements and Evaluation (SQuaRE). This standard helps in organizing and enhancing the process related to software quality requirements and their evaluations. In reality, ISO-25000 replaces the two old ISO standards, i.e. ISO-9126 and ISO-14598.
SQuaRE is divided into sub-parts such as:
- ISO 2500n - Quality Management Division
- ISO 2501n - Quality Model Division
- ISO 2502n - Quality Measurement Division
- ISO 2503n - Quality Requirements Division
- ISO 2504n - Quality Evaluation Division
The main contents of SQuaRE are:
- Terms and definitions
- Reference Models
- General guide
- Individual division guides
- Standard related to Requirement Engineering (i.e. specification, planning, measurement and evaluation process)
ISO/IEC 12119
This standard deals with software packages delivered to the client. It does not focus or deal with the clients’ production process. The main contents are related to the following items:
- Set of requirements for software packages.
- Instructions for testing a delivered software package against the specified requirements.
Miscellaneous
Some of the other standards related to QA and Testing processes are mentioned below:
| Standard | Description |
|---|---|
| IEEE 829 | A standard for the format of documents used in different stages of software testing. |
| IEEE 1061 | A methodology for establishing quality requirements, identifying, implementing, analysing, and validating the process, and product of software quality metrics. |
| IEEE 1059 | Guide for Software Verification and Validation Plans. |
| IEEE 1008 | A standard for unit testing. |
| IEEE 1012 | A standard for Software Verification and Validation. |
| IEEE 1028 | A standard for software inspections. |
| IEEE 1044 | A standard for the classification of software anomalies. |
| IEEE 1044-1 | A guide for the classification of software anomalies. |
| IEEE 830 | A guide for developing system requirements specifications. |
| IEEE 730 | A standard for software quality assurance plans. |
| IEEE 1061 | A standard for software quality metrics and methodology. |
| IEEE 12207 | A standard for software life cycle processes and life cycle data. |
| BS 7925-1 | A vocabulary of terms used in software testing. |
| BS 7925-2 | A standard for software component testing. |
MT - 69 - Regression testing and its types !
Regression Testing is a testing of a program which was previously tested and went through any modification. It is done to ensure that the defects have not been introduced or new defects has not been uncovered in the other areas of the program. It is performed when a software or its environment is changed. Regression testing is the process of testing changes to computer programs to make sure that the older programming still works with the new changes. They are subcategorised into 3 types :
Unit regression testing:
Testing the only one particular fixed unit or feature .
Region regression testing:
Testing the changes and the impact regions is called Regional Regression testing. In this type of regression testing only select modules are tested which are connected to the changed modules
Full regression testing:
Testing the changes and all the remaining features of the system.It is normally done when the changes are done in the root of the product or whenever the modifications or changes are more in the product or a larger area of the product is impacted.
Excerpts :
If any modification is done in one module and if the module is some where linked with the other two modules , then in this case regional regression is preferred over the full regression testing.If modifications are done in many modules in the project and if its difficult to recognize the effected modules then we do full regression testing rather than taking risk.
Unit regression testing:
Testing the only one particular fixed unit or feature .
Region regression testing:
Testing the changes and the impact regions is called Regional Regression testing. In this type of regression testing only select modules are tested which are connected to the changed modules
Full regression testing:
Testing the changes and all the remaining features of the system.It is normally done when the changes are done in the root of the product or whenever the modifications or changes are more in the product or a larger area of the product is impacted.
Excerpts :
If any modification is done in one module and if the module is some where linked with the other two modules , then in this case regional regression is preferred over the full regression testing.If modifications are done in many modules in the project and if its difficult to recognize the effected modules then we do full regression testing rather than taking risk.
MT - 68 - Testware in terms of testing !
The artifacts that are produced during the testing process which are required to plan, design, and execute tests is called Testware. It includes artifacts produced during the test process required to plan, design, and execute tests, such as documentation, scripts, inputs, expected results, set-up and clear-up procedures, files, databases, environment, and any additional software or utilities used in testing.In short the testware includes all the materials used to perform a test like test cases, testplan, scripts , test results, etc.
Tuesday, 9 February 2016
MT - 67 - Relationship between Use case , Include and Extend in terms of testing !!
These two type of relationships are used in use case models .The UML( Unified Modelling Language) describes the relationship between usecases , <<include>> and <<exclude>> relationship. Before seeing the relationship between these three terms lets see about the use case modelling. Use Cases describes a logical task that may be performed by the system. The Use Case description describes the interaction between the system and the outside world. UML is used to create specification for the system based on the use cases.Use Case corresponds to a logical unit of work, so that as a rule of thumb it is typically,
performed by one person, in one place, at one time,
leaves the business data in a consistent state and
generates some business value.
The Use Case steps are usually arranged into a Basic Flow and Alternative Flows.The Basic Flow has other names, such as the Main Success Scenario or Happy Day scenario. It describes the steps that are required for a straightforward (but not always the simplest) execution of the Use Case. It sets aside the panoply of possibilities within the Use Case so that we can see the essence of the thing.
The Alternative Flows are also known by other names, such as exceptions or extensions. Each one describes some variation from the steps in the Basic Flow. Alternative Flows can also be overlaid on top of other Alternative Flows. Within a single execution of the Use Case – a single Scenario – any number of Alternative Flows may be invoked
Lets take an example of use case and relate it to the <<Include>> and <<extend>> relationship :
Eg : Use Case: “Take Customer Order”
Basic Flow:
1. Actor enters Customer details
2. Actor enters code for product required
3. System displays Product details
4. Actor enters quantity required
5. Actor enters Payment details
6. System saves Customer Order
Alternative Flows:
[multiple products]
After step 4, when the Actor enters the quantity required,
Repeat steps 2 to 4 for additional Products
Resume at step 5, to enter Payment details
 This diagram defines the use case with the basic flow.
This diagram defines the use case with the basic flow.
Now here comes the concept of <<include>> relationship, The «include» relationship allows us to include the steps from one Use Case into another.
This is valuable when the included steps occur as a recognisable sequence in many
different contexts.
In the above example , we need to capture the Customer’s details. After further analysis, we may find that there are other Use Cases where we also need to record the Customer’s details.Furthermore, we will find that there are a number of ways of doing this, for example, we may need to capture them as a new customer or recall them as an existing customer. So long as the steps required to capture the Customer’s details are not trivial, it becomes more economic to extract them into a separate flow, which we may call “Identify Customer”. See the picture below :

Now , the seperate use caseUse Case: “Identify Customer” will be as
Basic Flow:
1. Actor enters search criteria, surname and postcode
2. System displays matching Customers
3. Actor selects Customer
4. System displays Customer details
5. Actor confirms Customer
Alternative Flows:
[new customer]
After step 2, when the System does not display the required Customer, Actor creates new
Customer,
1. Actor selects to add new Customer
2. Actor enters Customer details
Resume at step 5, to confirm Customer
We now modify the base Use Case “Take Customer Order” to refer to the included Use Case “Identify Customer”. The very first use case will look like
Use Case: “Take Customer Order”
Basic Flow:
1. Actor records Customer details, include (Identify Customer)
2. Actor enters code for Product required
3. System displays Product details
4. Actor enters quantity required
5. Actor enters Payment details
6. System saves Customer Order
Alternative Flows:
[multiple products]
After step 4, when the Actor enters the quantity required,
Repeat steps 2 to 4 for additional Products
Resume at step 5, to enter Payment details
So when we execute the Use Case “Take Customer Order” step 1 tells us to execute all the steps of “Identify Customer”, including the possibility of all its Alternative Flows. The name of the included Use Case should be highlighted by placing it in parentheses or quotation marks.
Now lets discuss <<extend>> relationship
The «extend» relationship allows us to modify the behaviour of the base Use Case. Suppose we want to sell products that are made to order and require a degree of customer specification. For these products we will need to record the customer’s additional requirements, such as size and colour. In this case we are adding something extra to the flow of the base Use Case.We could do this as an Alternative Flow, thus: the steps will be like :
Use Case: “Take Customer Order”
Basic Flow:
1. Actor records Customer details include (Identify Customer)
2. Actor enters code for product required
3. System displays product details
4. Actor enters quantity required
5. Actor enters payment details
6. System saves Customer Order
Alternative Flows:
[multiple products]
After step 4, when the Actor enters the quantity required,
Repeat steps 2 to 4 for additional products
Resume at step 5, to enter payment details
[customer specified product]
At step 3, when the System displays the Product details, if the product requires customer
specified features,
1. Actor enters customer specified requirements, such as size and colour
Resume at step 4, to enter quantity required, until step 6 where the Customer Order is saved.
At this step the additional customer-specific product details must also be saved
 The «extend» relationship says that we execute the base Use Case but when we get to a
specified point in the flow, if the right conditions are met, we perform some different steps.
Clearly this is very similar to an Alternative Flow.
The «extend» relationship says that we execute the base Use Case but when we get to a
specified point in the flow, if the right conditions are met, we perform some different steps.
Clearly this is very similar to an Alternative Flow.
When to use «include» and when to use «extend»
1. Do the additional steps constitute a single contiguous set of steps?
Yes, you are adding steps at one place in the flow – use «include».
No, you need to modify the base Use Case in more than one place – use «extend».
2. Do the additional steps make sense on their own?
Yes – use «include».
No – use «extend».
Summary:
Include = reuse of functionality
Extends = new and/or optional functionality
Extends is used when you understand that your use case is too much complex. So you extract the complex steps into their own "extension" use cases.
Include is used when you see common behaviour in two use cases. So you abstract out the common behaviour into a separate "abstract" use case.
Extend is optional from user point of view, it may or may not occur.
performed by one person, in one place, at one time,
leaves the business data in a consistent state and
generates some business value.
The Use Case steps are usually arranged into a Basic Flow and Alternative Flows.The Basic Flow has other names, such as the Main Success Scenario or Happy Day scenario. It describes the steps that are required for a straightforward (but not always the simplest) execution of the Use Case. It sets aside the panoply of possibilities within the Use Case so that we can see the essence of the thing.
The Alternative Flows are also known by other names, such as exceptions or extensions. Each one describes some variation from the steps in the Basic Flow. Alternative Flows can also be overlaid on top of other Alternative Flows. Within a single execution of the Use Case – a single Scenario – any number of Alternative Flows may be invoked
Lets take an example of use case and relate it to the <<Include>> and <<extend>> relationship :
Eg : Use Case: “Take Customer Order”
Basic Flow:
1. Actor enters Customer details
2. Actor enters code for product required
3. System displays Product details
4. Actor enters quantity required
5. Actor enters Payment details
6. System saves Customer Order
Alternative Flows:
[multiple products]
After step 4, when the Actor enters the quantity required,
Repeat steps 2 to 4 for additional Products
Resume at step 5, to enter Payment details

Now here comes the concept of <<include>> relationship, The «include» relationship allows us to include the steps from one Use Case into another.
This is valuable when the included steps occur as a recognisable sequence in many
different contexts.
In the above example , we need to capture the Customer’s details. After further analysis, we may find that there are other Use Cases where we also need to record the Customer’s details.Furthermore, we will find that there are a number of ways of doing this, for example, we may need to capture them as a new customer or recall them as an existing customer. So long as the steps required to capture the Customer’s details are not trivial, it becomes more economic to extract them into a separate flow, which we may call “Identify Customer”. See the picture below :

This picture denotes shared common steps for the use case
Basic Flow:
1. Actor enters search criteria, surname and postcode
2. System displays matching Customers
3. Actor selects Customer
4. System displays Customer details
5. Actor confirms Customer
Alternative Flows:
[new customer]
After step 2, when the System does not display the required Customer, Actor creates new
Customer,
1. Actor selects to add new Customer
2. Actor enters Customer details
Resume at step 5, to confirm Customer
We now modify the base Use Case “Take Customer Order” to refer to the included Use Case “Identify Customer”. The very first use case will look like
Use Case: “Take Customer Order”
Basic Flow:
1. Actor records Customer details, include (Identify Customer)
2. Actor enters code for Product required
3. System displays Product details
4. Actor enters quantity required
5. Actor enters Payment details
6. System saves Customer Order
Alternative Flows:
[multiple products]
After step 4, when the Actor enters the quantity required,
Repeat steps 2 to 4 for additional Products
Resume at step 5, to enter Payment details
So when we execute the Use Case “Take Customer Order” step 1 tells us to execute all the steps of “Identify Customer”, including the possibility of all its Alternative Flows. The name of the included Use Case should be highlighted by placing it in parentheses or quotation marks.
Now lets discuss <<extend>> relationship
The «extend» relationship allows us to modify the behaviour of the base Use Case. Suppose we want to sell products that are made to order and require a degree of customer specification. For these products we will need to record the customer’s additional requirements, such as size and colour. In this case we are adding something extra to the flow of the base Use Case.We could do this as an Alternative Flow, thus: the steps will be like :
Use Case: “Take Customer Order”
Basic Flow:
1. Actor records Customer details include (Identify Customer)
2. Actor enters code for product required
3. System displays product details
4. Actor enters quantity required
5. Actor enters payment details
6. System saves Customer Order
Alternative Flows:
[multiple products]
After step 4, when the Actor enters the quantity required,
Repeat steps 2 to 4 for additional products
Resume at step 5, to enter payment details
[customer specified product]
At step 3, when the System displays the Product details, if the product requires customer
specified features,
1. Actor enters customer specified requirements, such as size and colour
Resume at step 4, to enter quantity required, until step 6 where the Customer Order is saved.
At this step the additional customer-specific product details must also be saved

When to use «include» and when to use «extend»
1. Do the additional steps constitute a single contiguous set of steps?
Yes, you are adding steps at one place in the flow – use «include».
No, you need to modify the base Use Case in more than one place – use «extend».
2. Do the additional steps make sense on their own?
Yes – use «include».
No – use «extend».
3. Do the additional steps occur in more than one base Use Case?
Yes – use «include».
No – use «extend».
Summary:
Include = reuse of functionality
Extends = new and/or optional functionality
Extends is used when you understand that your use case is too much complex. So you extract the complex steps into their own "extension" use cases.
Include is used when you see common behaviour in two use cases. So you abstract out the common behaviour into a separate "abstract" use case.
Extend is optional from user point of view, it may or may not occur.
Wednesday, 3 February 2016
MT - 66 - Test Effectiveness and Test Efficiency
Test Efficiency :
The ratio of the effective or useful output to the total input in any system.Therefore, efficiency is an attribute which means to maximize the useful output for a given input reducing wastage or losses. Efficiency cannot be more than a 100%, in a sense that a 100% efficient system will have zero losses. Test efficiency is not only about test execution alone, but all or most of test activities, like test planning, comprehension, test cases creation, review, execution, defect tracking and closure. TE is not just one single derivation but a number of calculations at each phase and activity of testing. What activities or phases one is interested in, what is particularly measured, depends on lot of other things, the type of project, complexity, availability of resources, the situation, customer requirement etc.
Test Efficiency = (Test Defects / (Test Defects + Acceptance Defects)) * 100
OR
Testing Efficiency = (No. of defects Resolved / Total No. of Defects Submitted)* 100
Test defects = Unit + Integration + System defects
Acceptance Defects = Bugs found by the customer
Test Effectiveness :
Effectiveness means the capability of producing an effect.Test effectiveness is to ensure quality and close the two quality gaps, namely producer’s quality gap and customer’s quality gap. As definition of quality goes, quality is both process and product quality which is meeting customer requirements and conformance to product specification.
Test Effectiveness = ((Defects removed in a phase) / (Defect injected + Defect escaped)) * 100
OR
Test effectiveness = Number of defects found divided by number of test cases executed.
OR
Test Effectiveness = Loss due to problems / Total resources processed by the system
Example :
The table shows the defect origin, on the X, where a defect was injected, where he belongs to? and on the Y, where the defect was detected.

Let us calculate the test effectiveness of the Integration testing activity:
Total number of defects of all origin found during Integration testing activity = 17
Total number of defects existing while entering in IT = (6+15+28) – (35) = 14
Total number of defects injected in the current stage = 14
Effectiveness of IT test phase = Total defects found in this phase/(No of defects existing + injected)
Effectiveness = 17/(14+14 ) * 100 = 60.7%
Difference Between these two :
- Efficiency - productivity metric and Effectiveness - quality metric!
- Efficiency is a productivity metrics meaning how fast one can do something. Hence Testing efficiency metric can be "No. of test cases executed per hour or per person day".Effectiveness is a quality metrics meaning how good a person is at testing. Hence Testing effectiveness metrics can be "No. of bugs identified by a tester in a given feature / Total no. of bugs identified in that feature".
-Effectiveness - How well the user achieves the goals they set out to achieve using the system (process).
Efficiency - The resources consumed in order to achieve their goals.
The ratio of the effective or useful output to the total input in any system.Therefore, efficiency is an attribute which means to maximize the useful output for a given input reducing wastage or losses. Efficiency cannot be more than a 100%, in a sense that a 100% efficient system will have zero losses. Test efficiency is not only about test execution alone, but all or most of test activities, like test planning, comprehension, test cases creation, review, execution, defect tracking and closure. TE is not just one single derivation but a number of calculations at each phase and activity of testing. What activities or phases one is interested in, what is particularly measured, depends on lot of other things, the type of project, complexity, availability of resources, the situation, customer requirement etc.
Test Efficiency = (Test Defects / (Test Defects + Acceptance Defects)) * 100
OR
Testing Efficiency = (No. of defects Resolved / Total No. of Defects Submitted)* 100
Test defects = Unit + Integration + System defects
Acceptance Defects = Bugs found by the customer
Test Effectiveness :
Effectiveness means the capability of producing an effect.Test effectiveness is to ensure quality and close the two quality gaps, namely producer’s quality gap and customer’s quality gap. As definition of quality goes, quality is both process and product quality which is meeting customer requirements and conformance to product specification.
Test Effectiveness = ((Defects removed in a phase) / (Defect injected + Defect escaped)) * 100
OR
Test effectiveness = Number of defects found divided by number of test cases executed.
OR
Test Effectiveness = Loss due to problems / Total resources processed by the system
Example :
The table shows the defect origin, on the X, where a defect was injected, where he belongs to? and on the Y, where the defect was detected.

Let us calculate the test effectiveness of the Integration testing activity:
Total number of defects of all origin found during Integration testing activity = 17
Total number of defects existing while entering in IT = (6+15+28) – (35) = 14
Total number of defects injected in the current stage = 14
Effectiveness of IT test phase = Total defects found in this phase/(No of defects existing + injected)
Effectiveness = 17/(14+14 ) * 100 = 60.7%
Difference Between these two :
- Efficiency - productivity metric and Effectiveness - quality metric!
- Efficiency is a productivity metrics meaning how fast one can do something. Hence Testing efficiency metric can be "No. of test cases executed per hour or per person day".Effectiveness is a quality metrics meaning how good a person is at testing. Hence Testing effectiveness metrics can be "No. of bugs identified by a tester in a given feature / Total no. of bugs identified in that feature".
-Effectiveness - How well the user achieves the goals they set out to achieve using the system (process).
Efficiency - The resources consumed in order to achieve their goals.
Monday, 1 February 2016
MT - 65 - Difference between "Defect" , "Failure" , "Bug" , "Mistake" , "Error" , "Fault"
Bug: If the Error found by testers are accepted as error by Developers. Then the error will called Bug.
Error: This is cause due to human actions like code is not following the standard, there is some mistake in syntax, or there is mistake in invocation of variable or might be there is some mistakes in which database connectivity code is faulty.This can be a misunderstanding of the internal state of the software, an oversight in terms of memory management, confusion about the proper way to calculate a value, etc.
Fault: When the product/software successfully launched in the market and running properly but due to any reason if it works unexpectedly is called Fault.
Failure: If the product fails to full fill the requirement, then it is called Failure. It is a deviation of software from its expected delivery or service.Failure are caused by environment or sometime due to mishandling of product.
Mistake : human interaction which produce an incorrect result which is also called error.
Defect: Any issue currently caught in that application that are deviating the actual result from the requirement, will taken as Defect.
“A mistake in coding is called error ,error found by tester is called defect, defect accepted by development team then it is called bug ,build does not meet the requirements then it Is failure.”
Error: This is cause due to human actions like code is not following the standard, there is some mistake in syntax, or there is mistake in invocation of variable or might be there is some mistakes in which database connectivity code is faulty.This can be a misunderstanding of the internal state of the software, an oversight in terms of memory management, confusion about the proper way to calculate a value, etc.
Fault: When the product/software successfully launched in the market and running properly but due to any reason if it works unexpectedly is called Fault.
Failure: If the product fails to full fill the requirement, then it is called Failure. It is a deviation of software from its expected delivery or service.Failure are caused by environment or sometime due to mishandling of product.
Mistake : human interaction which produce an incorrect result which is also called error.
Defect: Any issue currently caught in that application that are deviating the actual result from the requirement, will taken as Defect.
“A mistake in coding is called error ,error found by tester is called defect, defect accepted by development team then it is called bug ,build does not meet the requirements then it Is failure.”
Sunday, 31 January 2016
MT - 64 - What is Test Coverage !
Test coverage is the measure of the amount or percentage of testing which is covered by a test set. Its gives information about the part of the system which has been covered in testing while running a test suite. Test coverage is defined as a technique which determines whether our test cases are actually covering the application code and how much code is exercised when we run those test cases.
Note : 100% percent test coverage doesn't means that 100% is tested and system is defect free.
Formula of test coverage :
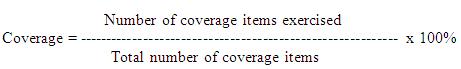
Test Coverage measurement
Test coverage can be best measured with the following 3 things:
-By mapping the requirements to the test cases.
-By seeing the test case status.
-By code coverage analysis.
Benefit of code coverage measurement:
-We can find the gaps easily in requirements, test cases and defects at an early level and code level.
-Time, scope and cost can be kept under control
-Defect prevention is possible at an early stage of project life cycle
-It can assure the quality of test
-It can help identify what portions of the code were actually touched for the release or fix
-We can create additional test cases for complete coverage
-It helps in finding areas of a program not exercised by a set of test cases
-The test coverage analysis can determine the decision points and important path made in the application which helps us to increase the test coverage.
Drawback of code coverage measurement:
- Drawback of code coverage measurement is that it measures coverage of what has been written, i.e. the code itself; it cannot say anything about the software that has not been written.
- If a specified function has not been implemented or a function was omitted from the specification, then structure-based techniques cannot say anything about them it only looks at a structure which is already there.
Note : 100% percent test coverage doesn't means that 100% is tested and system is defect free.
Formula of test coverage :
Test Coverage measurement
Test coverage can be best measured with the following 3 things:
-By mapping the requirements to the test cases.
-By seeing the test case status.
-By code coverage analysis.
Benefit of code coverage measurement:
-We can find the gaps easily in requirements, test cases and defects at an early level and code level.
-Time, scope and cost can be kept under control
-Defect prevention is possible at an early stage of project life cycle
-It can assure the quality of test
-It can help identify what portions of the code were actually touched for the release or fix
-We can create additional test cases for complete coverage
-It helps in finding areas of a program not exercised by a set of test cases
-The test coverage analysis can determine the decision points and important path made in the application which helps us to increase the test coverage.
Drawback of code coverage measurement:
- Drawback of code coverage measurement is that it measures coverage of what has been written, i.e. the code itself; it cannot say anything about the software that has not been written.
- If a specified function has not been implemented or a function was omitted from the specification, then structure-based techniques cannot say anything about them it only looks at a structure which is already there.
MT - 63 - Absence of error fallacy !
This is one of the principles of testing given by ISTQB. It says that if a system built is unusable from user point of view then there is no use of testing it and finding faults and fixing them. The system built should be in accordance with the user requirements. In other words we can say that customers are more interested in the usability of the software rather than getting a error-free software. The system developed should help them in completing their tasks effectively and efficiently. For the customers usable software is more important than a error free software. The people and organizations who buy and use it to aid in their day-to-day tasks - are not interested in defects or numbers of defects, except when they are directly affected by the instability of the software.
Saturday, 30 January 2016
MT - 62 - Orthogonal Array(OATS) !
Before discussing about orthogonal array let me take an example of a real time testing scenario. Suppose there is a requirement of testing where we need to test 3 parameters with 3 different values in a system. So here to do exhaustive testing and see the response of every possible input we need to have 27 test data sets.
So here comes the concept of Orthogonal arrays.This technique is used when we have to test with huge number data having many permutations and combinations.This technique maximizes the coverage with lesser number of test cases. I'd say this technique guarantees 100% coverage with comparatively lesser no of cases.
Now we map each values with the parameters. To do the mapping we need to identify all the parameters(also called as factors and values. Then make a table with all the possible combinations saying that each row is unique So here we can see that all the permutations and combinations are possible in 9 cases only. We can write our test sets based on the parameters and values.
Now once the array is created and we do testing there is a possibility of defects. There may be a single mode or multimode faults which we need to confirm seeing the parameters and values. Let's see it one by one :
Single Mode Faults - Single mode faults occur only due to one parameter. For example, in above Orthogonal array if test cases 7, 8 and 9 show error, we can expect that value 3 of parameter 1 is causing the error. Likewise we can detect as well as isolate the error.
Double Mode Fault - Double mode fault is caused by the two specific parameters values interacting together. Such an interaction is a harmful interaction between interacting parameters.
Multimode Faults - If more than two interacting components produce the consistent erroneous output, then it is a multimode fault. Orthogonal array detects the multimode faults.
Some important points :
- Creates an efficient and concise test set with many fewer test cases than testing all combinations
of all variables.
- This is a type of black box testing techniques.
-Orthogonal arrays can be applied in user interface testing, system testing, regression testing, configuration testing and performance testing
-OAT, is a systematic and statistical approach to pairwise interactions.
- Test cycle time is reduced
So here comes the concept of Orthogonal arrays.This technique is used when we have to test with huge number data having many permutations and combinations.This technique maximizes the coverage with lesser number of test cases. I'd say this technique guarantees 100% coverage with comparatively lesser no of cases.
Now we map each values with the parameters. To do the mapping we need to identify all the parameters(also called as factors and values. Then make a table with all the possible combinations saying that each row is unique So here we can see that all the permutations and combinations are possible in 9 cases only. We can write our test sets based on the parameters and values.
| Test data sets ↓ | Parameter 1 | Parameter 2 | Parameter 3 |
|---|---|---|---|
| 1 | Value 1 | Value 1 | Value 3 |
| 2 | Value 1 | Value 2 | Value 2 |
| 3 | Value 1 | Value 3 | Value 1 |
| 4 | Value 2 | Value 1 | Value 2 |
| 5 | Value 2 | Value 2 | Value 1 |
| 6 | Value 2 | Value 3 | Value 3 |
| 7 | Value 3 | Value 1 | Value 1 |
| 8 | Value 3 | Value 2 | Value 3 |
| 9 | Value 3 | Value 3 | Value 2 |
Single Mode Faults - Single mode faults occur only due to one parameter. For example, in above Orthogonal array if test cases 7, 8 and 9 show error, we can expect that value 3 of parameter 1 is causing the error. Likewise we can detect as well as isolate the error.
Double Mode Fault - Double mode fault is caused by the two specific parameters values interacting together. Such an interaction is a harmful interaction between interacting parameters.
Multimode Faults - If more than two interacting components produce the consistent erroneous output, then it is a multimode fault. Orthogonal array detects the multimode faults.
Some important points :
- Creates an efficient and concise test set with many fewer test cases than testing all combinations
of all variables.
- This technique exercises some of the complex combinations of all the variables.
- It is simpler to generate and less error prone than test sets created by hand.- This is a type of black box testing techniques.
-Orthogonal arrays can be applied in user interface testing, system testing, regression testing, configuration testing and performance testing
-OAT, is a systematic and statistical approach to pairwise interactions.
- Test cycle time is reduced
Saturday, 23 January 2016
MT - 61 - Defect Density !
Defects are considered to be the unexpected behaviour of the system with respect to the client requirements. The purpose of testing is to bring the confidence in the built system by mapping them with requirements. During testing we log lot of defects, some of them gets cancelled and some of them gets approved. From the management's perspective we need to have a track over the defects , its density and occurrence.
Defect Density is defined as the number of confirmed defects in software/module during a specific period of testing\development divided by the size of the software/module. The count may be used to ensure the correct time for release.

Here, size may be the number of lines of code or may be measured using FP(Funtion Points).
Number of defects represents the count of confirmed defects.
The defect density is calculated over a period based on the organisation standards.
Defect density can be affected by :
- The complexity of code
- Less time to test more code
- Unskilled testers
Advantages
- To compare the relative no of defects in various components so that risky components may be identified
-For comparing software/products so that quality of each software/product can be quantified and resources focused towards those with low quality.
-It helps measure the testing effectiveness
-It can be helpful in estimating the testing and rework due to bugs
-It can estimate the remaining defects in the software
-Before the release we can determine whether our testing is sufficient
Defect Density is defined as the number of confirmed defects in software/module during a specific period of testing\development divided by the size of the software/module. The count may be used to ensure the correct time for release.
Here, size may be the number of lines of code or may be measured using FP(Funtion Points).
Number of defects represents the count of confirmed defects.
The defect density is calculated over a period based on the organisation standards.
Defect density can be affected by :
- The complexity of code
- Less time to test more code
- Unskilled testers
Advantages
- To compare the relative no of defects in various components so that risky components may be identified
-For comparing software/products so that quality of each software/product can be quantified and resources focused towards those with low quality.
-It helps measure the testing effectiveness
-It can be helpful in estimating the testing and rework due to bugs
-It can estimate the remaining defects in the software
-Before the release we can determine whether our testing is sufficient
MT - 60 - Testing Techniques !
There is always a confusion between testing techniques and testing methods. So lets talk about testing techniques here.. There are basically two types of testing techniques : Static and Dynamic.
These two techniques can be further sub-categorized into various types.
Dynamic techniques are subdivided into three more categories: specification-based (black-box, also known as behavioural techniques), structure-based (white-box or structural techniques) and experience-based. Specification-based techniques include both functional and non-functional techniques (i.e. quality characteristics).
static testing techniques do not execute the code being examined and are generally used before any tests are executed on the software.

These two techniques can be further sub-categorized into various types.
Dynamic techniques are subdivided into three more categories: specification-based (black-box, also known as behavioural techniques), structure-based (white-box or structural techniques) and experience-based. Specification-based techniques include both functional and non-functional techniques (i.e. quality characteristics).
static testing techniques do not execute the code being examined and are generally used before any tests are executed on the software.
Tuesday, 19 January 2016
MT - 59 - Difference between white box and Black box testing
This is a basic question asked in many interviews. Lets see the differences in tabular form :
Black Box testing
|
White Box testing
|
Black Box testing is a testing method in which we consider the system
as a black box, we give input and check the output. Here the tester need not
to have the knowledge of internal structure.
|
White box testing is a testing method in which the tester needs to
know the internal structure and design of the system. The system is
considered as white box or glass box.
|
Test Cases are written based on the basis of the requirements.
|
Test cases are written on the basis of detailed design.
|
Programming/Coding knowledge is not required
|
Programming/Coding knowledge is required
|
Also known as functional testing, it is applicable to higher levels
like acceptance and system testing
|
Also known as structural testing , it is applicable to lower level of
testing like unit testing
|
There is a separate team of
Testers to do Black box testing
|
Usually Developers are responsible for White box testing
|
This type of testing always focuses on what
is performing/ carried out
|
This type of testing always focuses on how it
is performing/ carried out
|
External Testing
|
Internal testing
|
Code optimization can’t be done and since the testing is not at
internal level so hidden errors can’t be caught at code level
|
Code Optimization can be done and hidden errors can be discovered.
|
Black box testing techniques are Equivalence partitioning , BVA ,
Error guessing , CE graphing, etc
|
White box testing techniques are path testing , branch testing ,
condition testing , loop testing , etc
|
Implementation knowledge is not required
|
Implementation knowledge is required
|
Monday, 18 January 2016
MT - 58 - When to stop the testing ?
Testing is a never ending process , we can't stop the testing saying that we have tested every thing and the system is defect free. There is always a possibility for defects ,it may be masked or latent.
There are some industry constraints on which we decide that we should stop or hold the testing :
-> Test execution has been completed with a certain number of passed cases so that test coverage is achieved.
-> There are no known critical bugs.Bug rate falls below a certain level, now testers are not getting any priority 1, 2, or 3 bugs.
-> Coverage of code, functionality, or requirements reaches a specified point.
-> Stop the Testing when deadlines like release deadlines or testing deadlines is very near
-> When the time allocated to the test team is expired and client doesn't wants the date to be extended.
-> When the allocated budget comes to an end.
-> Stop the Testing when the period of beta testing / alpha testing gets over.
There are some industry constraints on which we decide that we should stop or hold the testing :
-> Test execution has been completed with a certain number of passed cases so that test coverage is achieved.
-> There are no known critical bugs.Bug rate falls below a certain level, now testers are not getting any priority 1, 2, or 3 bugs.
-> Coverage of code, functionality, or requirements reaches a specified point.
-> Stop the Testing when deadlines like release deadlines or testing deadlines is very near
-> When the time allocated to the test team is expired and client doesn't wants the date to be extended.
-> When the allocated budget comes to an end.
-> Stop the Testing when the period of beta testing / alpha testing gets over.
MT - 57 - How Incident Management works ?
Incident is a common name given to the term defect , bug , problem , fault or failure. Simply any deviation of the actual results from the expected results or any questionable behavior of the system is named as incident.
Some important things to consider about incidents :
- There are various causes of incidents like mis-configuration or failure of the test environment,corrupted test data, bad tests, invalid expected results and tester mistakes.
- Incident is about the questionable behavior of the system , all the incidents may not be a true defect. We make a record of all the incidents what we observed so that we can follow up on it and take necessary actions if required.
- Incidents can be logged along all the testing phases , development and reviews.
- Most commonly defects are reported against the code or the system itself , but defects can be reported against requirements and design specifications, user and operator guides and tests.
- Incident reports are used to provide programmers, managers and others with detailed information about the behavior observed and the defect. It is to support the analysis of trends in aggregate defect data, either for understanding more about a particular set of problems or tests or for understanding and reporting the overall level of system quality.
- While logging a Incident we can give as much information as we can. Incidents may be defects or any mis-behave of the system so the details may help the management and development teams in finding out the issues.
- IEEE 829 - Incident Report Template contains :
Test incident report identifier Summary Incident description (inputs, expected results, actual results, anomalies, date and time, procedure step, environment, attempts to repeat, testers and observers) Impact
- Incident report life cycle :


Every Incident goes through a life cycle. All incident reports move through a series of clearly identified states after being reported. After an incident is reported, a peer tester or test manager reviews the report. If successful in the review, the incident report becomes opened, so now the project team must decide whether or not to repair the defect. If the defect is to be repaired, a programmer is assigned to repair it. Once the programmer believes the repairs are complete, the incident report returns to the tester for confirmation testing. If the confirmation test fails, the incident report is re-opened and then re-assigned. Once the tester confirms a good repair, the incident report is closed. No further work remains to be done. In any state other than rejected, deferred or closed, further work is required on the incident prior to the end of this project. In a rejected, deferred or closed state, the incident report will not be assigned to an owner.
- Standard Incident Procedures :
->Identification - detect or report the incident
->Registration - the incident is registered
->Categorization - the incident is categorized by priority, severity ,SLA etc.
->Prioritization - the incident is prioritized for better utilization of the resources and the Support Staff time
->Diagnosis - reveal the full symptom of the incident in details
->Escalation - should the Support Staff need support from other organizational units
->Investigation and diagnosis - if no existing solution from the past could be found the incident is investigated and root cause found
->Resolution and recovery - once the solution is found the incident is resolved
->Incident closure - this is the last phase where Incidents are closed
Some important things to consider about incidents :
- There are various causes of incidents like mis-configuration or failure of the test environment,corrupted test data, bad tests, invalid expected results and tester mistakes.
- Incident is about the questionable behavior of the system , all the incidents may not be a true defect. We make a record of all the incidents what we observed so that we can follow up on it and take necessary actions if required.
- Incidents can be logged along all the testing phases , development and reviews.
- Most commonly defects are reported against the code or the system itself , but defects can be reported against requirements and design specifications, user and operator guides and tests.
- Incident reports are used to provide programmers, managers and others with detailed information about the behavior observed and the defect. It is to support the analysis of trends in aggregate defect data, either for understanding more about a particular set of problems or tests or for understanding and reporting the overall level of system quality.
- While logging a Incident we can give as much information as we can. Incidents may be defects or any mis-behave of the system so the details may help the management and development teams in finding out the issues.
- IEEE 829 - Incident Report Template contains :
Test incident report identifier Summary Incident description (inputs, expected results, actual results, anomalies, date and time, procedure step, environment, attempts to repeat, testers and observers) Impact
- Incident report life cycle :
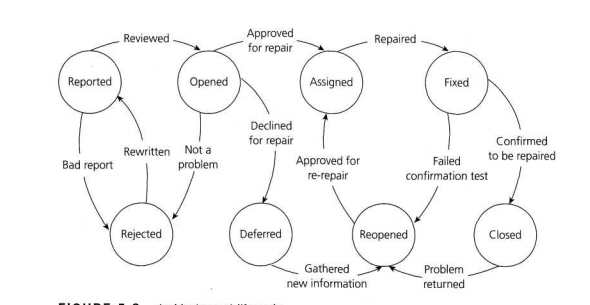
Every Incident goes through a life cycle. All incident reports move through a series of clearly identified states after being reported. After an incident is reported, a peer tester or test manager reviews the report. If successful in the review, the incident report becomes opened, so now the project team must decide whether or not to repair the defect. If the defect is to be repaired, a programmer is assigned to repair it. Once the programmer believes the repairs are complete, the incident report returns to the tester for confirmation testing. If the confirmation test fails, the incident report is re-opened and then re-assigned. Once the tester confirms a good repair, the incident report is closed. No further work remains to be done. In any state other than rejected, deferred or closed, further work is required on the incident prior to the end of this project. In a rejected, deferred or closed state, the incident report will not be assigned to an owner.
- Standard Incident Procedures :
->Identification - detect or report the incident
->Registration - the incident is registered
->Categorization - the incident is categorized by priority, severity ,SLA etc.
->Prioritization - the incident is prioritized for better utilization of the resources and the Support Staff time
->Diagnosis - reveal the full symptom of the incident in details
->Escalation - should the Support Staff need support from other organizational units
->Investigation and diagnosis - if no existing solution from the past could be found the incident is investigated and root cause found
->Resolution and recovery - once the solution is found the incident is resolved
->Incident closure - this is the last phase where Incidents are closed
Subscribe to:
Posts (Atom)